
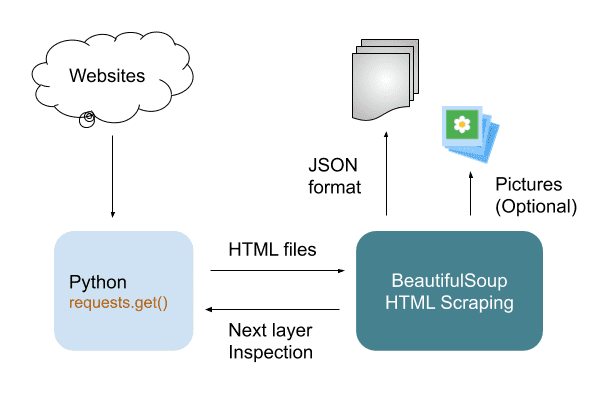
Web Scraping means navigating structured elements on a website, and deeply going to next layers. Incoming big data will be retrieved and formated in desired styles. We apply Python BeautifulSoup to a simple example for scraping with step-by-step tutorials.
All codes here are not complicated, so you can easily understand even though you are still students in school. To benefit your learning, we will provide you download link to a zip file thus you can get all source codes for future usage.
Estimated reading time: 10 minutes
EXPLORE THIS ARTICLE
TABLE OF CONTENTS
BONUS
Source Code Download
We have released it under the MIT license, so feel free to use it in your own project or your school homework.
Download Guideline
- Prepare Python environment for Windows by clicking Python Downloads, or search a Python setup pack for Linux.
- The pack of Windows version also contains pip install for you to obtain more Python libraries in the future.
THE BASICS
Python Web Scraping
Web pages are written using HTML to be structured texts. Therefore, people can obtain organized information of websites by scraping. Because Python is good at that, we will introduce its library BeautifulSoup in the article.
What is BeautifulSoup?
BeautifulSoup version 4 is a famous Python library for web scraping. In addition, there was BeautifulSoup version 3, and support for it will be dropped on or after December 31, 2020. People had better learn newer versions. Below is the definition from BeautifulSoup Documentation.
BeautifulSoup Installation
If you already download and setup Python and its tool pip in Windows or Linux, you can install BeautifulSoup 4 package bs4 by pip install command lines, and then check the result by pip show.
C:\>pip install bs4
C:\>pip show bs4
Name: bs4
Version: 0.0.1
Summary: Screen-scraping library
Home-page: https://pypi.python.org/pypi/beautifulsoup4
Author: Leonard Richardson
Author-email: leonardr@segfault.org
License: MIT
Location: c:\python\python37\lib\site-packages
Requires: beautifulsoup4
Required-by:
Scraping An Example Website
We should choose an example website to start. Focusing only on the content about laptop computer, thus the portion of an Indian shopping website, Snapdeal Laptops, will be suitable to our target.
There are two layers, top layer for a product list and bottom layer for details in specification. For safety, we suggest a process of saving pages and then retrieve data from them. Therefore, the page contents along with images are downloaded. Below is the running process.
C:\>python bs4crawler.py
Saved: https://www.snapdeal.com/products/computers-laptops?sort=plrty
Saved: https://www.snapdeal.com/product/hp-2rc10pa-250-g6-intel/620566671636
Downloaded: https://n1.sdlcdn.com/imgs/i/z/3/230X258_sharpened/HP-2RC10PA-250-G6-Intel-SDL652710699-1-e49b8.jpeg
Saved: https://www.snapdeal.com/product/lenovo-ideapad-81g200cain-notebook-core/675387603791
Downloaded: https://n4.sdlcdn.com/imgs/i/k/n/230X258_sharpened/Lenovo_Ideapad_81G200CAIN_Notebook_Core_SDL948306451_1_51fdf-b20e2.jpg
.....
Saved: https://www.snapdeal.com/product/dell-inspiron-inspiron-3584-thin/674627493020
Downloaded: https://n4.sdlcdn.com/imgs/i/v/h/large/Dell-Inspiron-Inspiron-3584-Thin-SDL642934625-1-218ae.jpeg
result.json total=20
Next, you will learn how to scaping web pages by BeautifulSoup. The result will be saved as JSON format in a file named result.json.
STEP 1
Finding How Web Pages Link
The previous section let us know what type of data we will meet, so we need to inspect these HTML structured texts to find entry points for BeautifulSoup scraping to start.
Finding The Relationship
Probably, the website you want to crawl has more layers than that in this example. As there is no general rule for various web pages, it is better to get a entry point that BeautifulSoup can start from by finding how web pages link.

Below lists the JSON-styled data related to a specific laptop computer. Except that the fields under "highlight" is found from layer 2, other fields come from layer 1. For example, "title" indicates the product name with brief specification, and "img_url" can be used to download product pictures.
{
"pogid": "638317853217",
"href": "https://www.snapdeal.com/product/hp-15-da0326tu-notebook-core/638317853217",
"img_url": "https://n1.sdlcdn.com/imgs/i/f/1/230X258_sharpened/HP_15_da0326tu_Notebook_Core_SDL722478060_1_f0e99-860ce.jpg",
"title": "HP 15-da0326tu 2018 15.6-inch FHD Laptop (7th Gen Intel Core i3-7100U/4GB/1TB/Windows 10/Integrated Graphics), Natural Silver",
"price": "Rs. 39,874",
"price_discount": "Rs. 31,974",
"discount": "20% Off",
"highlight": {
"Warranty Period": "1 Year",
"Usage": "Business",
"Resolution": "1920x1080 (Full HD)",
"Base Clock Speed (in GHz)": "2.4",
"Backlit Keyboard": "No"
}
}
What to Inspect in Layer 1
From the view of HTML document, let us continue inspecting Layer 1 in file laptop.html. In other words, by going through HTML structured text, BeautifulSoup can locate the key feature of class="product-tuple-image" for scraping items like <a pogId=, <a href=, <source srcset=, and <img title= to be pogid, href, img_url, and title, respectively. Where href directs to url in Layer 2 for that product.
<div class="product-tuple-image ">
<a class="dp-widget-link" pogId="638317853217" href="https://www.snapdeal.com/product/hp-15-da0326tu-notebook-core/638317853217" data-position="0;85" target="_blank">
<div class="bg-image hidden"></div>
<picture class="picture-elem">
<source srcset="https://n1.sdlcdn.com/imgs/i/f/1/large/HP_15_da0326tu_Notebook_Core_SDL722478060_1_f0e99-860ce.jpg" title="HP 15-da0326tu 2018 15.6-inch FHD Laptop (7th Gen Intel Core i3-7100U/4GB/1TB/Windows 10/Integrated Graphics), Natural Silver" media="(min-width: 1430px)" class="product-image" >
<img class="product-image " src="https://n1.sdlcdn.com/imgs/i/f/1/230X258_sharpened/HP_15_da0326tu_Notebook_Core_SDL722478060_1_f0e99-860ce.jpg" title="HP 15-da0326tu 2018 15.6-inch FHD Laptop (7th Gen Intel Core i3-7100U/4GB/1TB/Windows 10/Integrated Graphics), Natural Silver">
</picture>
<input type="hidden" value="https://n1.sdlcdn.com/imgs/i/f/1/64x75/HP_15_da0326tu_Notebook_Core_SDL722478060_1_f0e99-860ce.jpg" class="compareImg" />
</a>
<div class="clearfix row-disc">
<div supc="SDL722478060" pogId="638317853217" cartId="" class="center quick-view-bar btn btn-theme-secondary ">
Quick View</div>
</div>
</div>
Similarly, with another feature of class="product-tuple-description", BeautifulSoup can continue scraping <span product-desc-price=, <span product-price=, and <div product-discount= to retrieve JSON fields price, price_discount, and discount. So far, all items in Layer 1 have been discovered.
<div class="product-tuple-description " >
<div class="product-desc-rating ">
<a class="dp-widget-link noUdLine" pogId="638317853217" href="https://www.snapdeal.com/product/hp-15-da0326tu-notebook-core/638317853217" hidOmnTrack="" target="_blank">
<p class="product-title " title="HP 15-da0326tu 2018 15.6-inch FHD Laptop (7th Gen Intel Core i3-7100U/4GB/1TB/Windows 10/Integrated Graphics), Natural Silver">HP 15-da0326tu 2018 15.6-inch FHD Laptop (7th Gen Intel Core i3-7100U/4GB/1TB/Windows 10/Integrated Graphics), Natural Silver</p>
<div class="product-price-row clearfix" >
<div class="lfloat marR10">
<span class="lfloat product-desc-price strike ">Rs. 39,874</span>
<span class="lfloat product-price" id="display-price-638317853217" display-price="31974" data-price="31974">Rs. 31,974</span>
</div>
<div class="product-discount">
<span>20% Off</span>
</div>
</div>
.......
What to Inspect in Layer 2
Further, BeautifulSoup traverses the HTML file of Layer 2 such as 638317853217.html. As mentioned previously, that is for detailed specification of laptops. The task in Layer 2 can be done by scraping items inside the feature of class="highlightsTileContent ".
<div class="highlightsTileContent highlightsTileContentTop clearfix">
<div class="p-keyfeatures kf-below-name">
<ul class="clearfix">
<li class='col-xs-8 reset-padding' title="Warranty Period:1 Year ">
<span class="list-circle"></span>
<span class="h-content">Warranty Period:1 Year</span>
</li>
<li class='col-xs-8 reset-padding' title="Usage:Business "><span class="list-circle"></span>
<span class="h-content">Usage:Business</span>
</li>
<li class='col-xs-8 reset-padding' title="Resolution:1920x1080 (Full HD) "><span class="list-circle"></span>
<span class="h-content">Resolution:1920x1080 (Full HD)</span>
</li>
<li class='col-xs-8 reset-padding' title="Base Clock Speed (in GHz):2.4 "><span class="list-circle"></span>
<span class="h-content">Base Clock Speed (in GHz):2.4</span>
</li>
<li class='col-xs-8 reset-padding' title="Backlit Keyboard:No "><span class="list-circle"></span>
<span class="h-content">Backlit Keyboard:No</span>
</li>
<li class='col-xs-8 reset-padding' title="View all item details"><span class="list-circle" style="visibility:hidden"></span>
<span class="h-content viewAllDetails"><a href="javascript: void(0)">View all item details</a></span>
</li>
</ul>
</div>
</div>
STEP 2
Scraping By Beautifulsoup
Before scraping, we got to introduce a popular Python library PyPI requests to get contents from websites. Then, BeautifulSoup will perform iteratedly in layers to convert all information into JSON-style data.
PyPI requests
PyPI requests is an elegant and simple HTTP library for Python. In the following paragraph, we leverage it to read text from web pages and save as HTML files. Of course, you can install it by issuing pip install requests in command box.
PyPI requests requests.get() not only get web pages, but also pull down binary data for pictures like that in download_image().
def get_web_page(url):
agent = {"User-Agent":'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
r = requests.get(url, headers=agent)
if r.status_code != 200:
print('Invalid url:', r.url)
return None
else:
r.encoding = 'utf-8'
return r.text
def download_image(img_url, dir):
r = requests.get(img_url)
if r.status_code != 200:
print('Download Err: '+r.url)
else :
print('Downloaded: '+r.url)
with open(dir + img_url.split('/')[-1], 'wb') as f:
f.write(r.content)
Python Scraping in Layer 1
Let us start from getLayer_1() in which each web page has been saved before BeautifulSoup parsing proceed.
Saving contents as backup is helpful for debuging. Once exceptions happens while BeautifulSoup scraping, it is hard for you to find again the exact content you need from massive web pages. In addition to that, too frequent data scraping may trigger prohibition of some websites.
For BeautifulSoup, the very first expression like soup = BeautifulSoup(page, 'html.parser') need to select one kind of parsers. The parser could be html.parser or html5lib, whose difference can be found in Differences between parsers.
Based on understanding about what the text structure is in STEP 1, we find prices from the class of product-tuple-description by using attrs={} with which BeautifulSoup anchors a lot of locations in this example. Apart from prices, pictures are done in the same way.
Layer 1 can discover data about titles, images, and prices. Importantly, you should notice that BeautifulSoup uses find_all() or find() to gather information for all pieces or one piece, like the usage in database.
def getLayer_1():
page = get_web_page(the_url)
if page == None :
return
print('Saved: ' + the_url)
fn = htm_dir + 'laptop.html'
with open(fn, 'w', encoding='UTF-8') as f:
f.write(page)
with open(fn, 'r', encoding='UTF-8') as f:
page = f.read()
soup = BeautifulSoup(page, 'html.parser')
images = soup.find_all('div', attrs={'class':'product-tuple-image'})
prices = soup.find_all('div', attrs={'class':'product-tuple-description'})
list = []
errors = ""
for i in range(0, len(images), 1) :
try:
img_url = images[i].find('img')['src']
except KeyError:
img_url = images[i].find('source')['srcset']
errors += images[i].find('a').prettify() + "\n\n"
discount_info = prices[i].find('div', attrs={'class':'product-discount'})
if discount_info == None :
discount_rate = "No Discount"
else :
discount_rate = discount_info.span.string
list.append({
'pogid':images[i].find('a')['pogid'],
'href': images[i].find('a')['href'],
'img_url': img_url,
'title': images[i].find('img')['title'],
'price': prices[i].find('span', attrs={'class':'product-desc-price'}).string,
'price_discount': prices[i].find('span', attrs={'class':'product-price'}).string,
'discount': discount_rate,
'highlight': getLayer_2(images[i].find('a')['href']),
})
download_image(img_url, img_dir)
print('result.json total='+str(len(list)))
with open('result.json', 'w', encoding='utf-8') as f:
json.dump(list, f, indent=2, ensure_ascii=False)
if (errors != "") :
with open("errors.log", 'w', encoding='UTF-8') as f:
f.write(errors)
For each page in Layer 2, 'highlight': getLayer_2() is called iteratedly to retrieve more. Finally, json.dump() save JSON-formated data as a file. Subsequently, let us go through steps for BeautifulSoup scraping in Layer 2 in next paragraph.
Python Scraping in Layer 2
Like the way in Layer 1, getLayer_2() find more product details by locating the class of highlightsTileContent. Then, in a loop, it store searched data in an array. You can check what is in this array in JSON style as discussed in STEP 1.
def getLayer_2(url):
page = get_web_page(url)
if page == None :
return []
fn = htm_dir + url.split('/')[-1]+'.html'
print('Saved: ' + url)
with open(fn, 'w', encoding='UTF-8') as f:
f.write(page)
with open(fn, 'r', encoding='UTF-8') as f:
page = f.read()
soup = BeautifulSoup(page, 'html.parser')
h_contents = soup.find('div', attrs={'class':'highlightsTileContent'}).find_all('span', attrs={'class':'h-content'})
array = dict()
for h_content in h_contents :
if h_content.string != 'View all item details' :
items = h_content.string.split(':')
array[items[0]] = items[1]
return array
STEP 3
Handling Exception
BeautifulSoup scraping won’t be smooth continuously, because the input HTML elements may be partial missing. In that case, you have to take actions to avoid interrupt, and keep the entire procedure going on.
Why Will Exceptions Probably Occur?
In laptop.html, if every product has identical fields, there will be no exception. However, when any product has less fields than that of other normal products, it could happen like what the following Python scripts express.
Always, you have to deal with every kind of exception, so as to prevent the scrapying process from interrupt. Imaging that programs suddenly exit due to errors after crawling several thousands of pieces, the loss won’t be little.
try:
img_url = images[i].find('img')['src']
except KeyError:
img_url = images[i].find('source')['srcset']
errors += images[i].find('a').prettify() + "\n\n";
discount_info = prices[i].find('div', attrs={'class':'product-discount'})
if discount_info == None :
discount_rate = "No Discount"
else :
discount_rate = discount_info.span.string
What Exceptions to Handle
Here list only two conditions. However, you may encounter extra ones when scrapying more and more web pages.
KeyError means the HTML element to search for does not exist. You may have been aware of an alternative HTML element to replace with, thus in this example, you can replace find('img')['src'] with find('source')['srcset']. However, if no alternation, just ignore it.
FINAL
Conclusion
We didn’t write detailed skills in BeautifulSoup Documentation, but show many opinions and directions about scraping in Python. Therefore, if you are not familiar with skills, please refer to online resources for practices.
If you want more computing resources for scraping, suggest to study the parallel execution in Python.
Thank you for reading, and we have suggested more helpful articles here. If you want to share anything, please feel free to comment below. Good luck and happy coding!
Suggested Reading
- 4 Practices for Python File Upload to PHP Server
- Compare Python Dict Index and Other 5 Ops with List