
The Googletrans Python library can implement multilingual chatbot examples such as a French chatbot. In general, the French stemmer, one of NLTK(Natural Language Toolkit) Snowball Stemmers, is able to parse French sentences and phases to achieve a French chatbot. Alternatively, we provide here another approach and will tell you the reason.
Although the NLTK Snowball Stemmer library supports only the following languages: Arabic, Danish, Dutch, English, Finnish, French, German,Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish and Swedish. For languages not included, the quick way to build a chatbot is translating forward and backward by the excellent translation library Googletrans in Python.
All codes here are not complicated, so you can easily understand even though you are still students in school. To benefit your learning, we will provide you download link to a zip file thus you can get all source codes for future usage.
Estimated reading time: 10 minutes
EXPLORE THIS ARTICLE
TABLE OF CONTENTS
BONUS
Source Code Download
We have released it under the MIT license, so feel free to use it in your own project or your school homework.
Download Guideline
- Install Python on Windows by clicking Python Downloads, or search a Python setup pack for Linux.
- The installation package for Windows also contains pip install, which allow you to obtain more Python libraries in the future.
SECTION 1
Structure of Chatbot
Continuing our previous post about chatbot deep learning using TensorFlow and NLTK, we suggest a method to create chatbots for most languages. Let’s use French chatbot as an example.
Like the previous article, the example had been only tested in Python 3.9 and TensorFlow 2.5.0 on Windows, and Python 3.6 and TensorFlow 1.5.0 on Ubuntu.
The Basics of Chatbot
Chatbot creation involves the technology of natural language processing. With help of NLTK, tokenization and stemming algorithms reduce natural language sentences into root words. After that, the intelligent phase for learning begins.
Chatbots learn the limited users’ intents that have been converted from textual words into numerical digits. The bag-of-words format of data represents the conversion results and cooperates with Python libraries to produce a TensorFlow model, which is intelligent and can be saved as files for future use.
At startup time, the chatbot loads an intelligent model. Once a user comes to the chatbot for talking, the model interprets natural language phrases and responds with a satisfied sentences. Technically, there is a level of confidence with the response according to the precision of training parameters in the intelligent model.
French Chatbot – A Multilingual Example
To build a chatbot for all languages encounters a difficulty, especially for logographic language such as Chinese. As NLTK Snowball Stemmer module tells us only a subset of alphabetic languages are supported. Therefore, we figure out an approach using translation.
In other words, when a user’s sentence is coming, translate it into English and submit it to the chatbot. Usually very soon, the chatbot gives an answer, and translate it backward to be the original language such as French. Truly, Googletrans Python library need to detect the user’s language in the beginning.
Based on Googletrans Python document, the translator can detect the language of source sentences, so an example of translating forward and backward are listed below. Where x.src indicates the source language and is equal to fr.
from Googletrans import Translator
trans = Translator()
french_phrase = "Donnez-moi des aliments ou des recettes"
x = trans.translate(dest=en, french_phrase) #forward (French to English)
y = trans.translate(dest=x.src, text=x.text) #backward (English to French)
| French (y.text) | English (x.text) |
|---|---|
| Donnez-moi des aliments ou des recettes | Give me foods or recipes |
The Structure of French Chatbot
Graphically, you can see that the learning process performs offline and primarily contributes to a model file and two others. The model file is of TensorFlow Keras and would be loaded within prediction process. Apart from that, the file containing root words is the stemming result, and tags file indicates how many categories the chatting intents belong to.
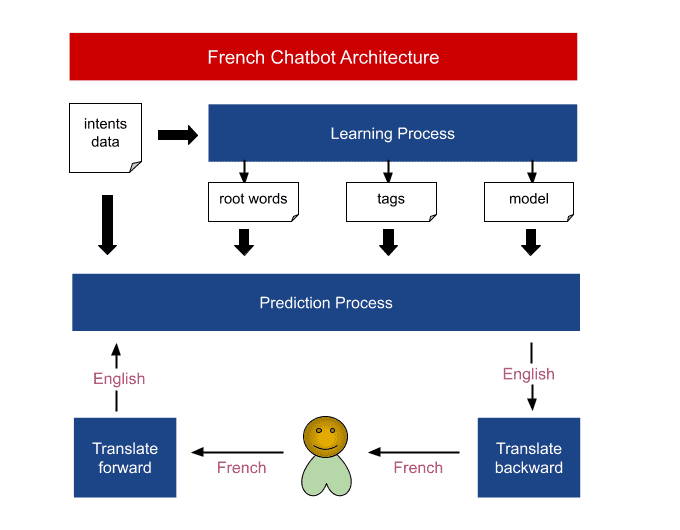
The prediction process performs online to serve customers. Customers speak French and want to get French answers, so translation forward and backward is necessary. The example sentences below demonstrate the fact that customers ask for meals.
You: Donnez-moi des aliments ou des recettes
Language: fr Text: Give me foods or recipes
You can browse by meal types or skip right to a recipe. What would you like? (confidence: 0.9999370574951172)
Bot: Vous pouvez parcourir les types de repas ou passer directement à une recette. Que désirez-vous?
SECTION 2
Googletrans in Python
Google translation API’s benefits us, and is easy to install, but have daily limits. In the section, we will talk about how to install it correctly, to use it and even to give advices.
Install Googletrans
Commonly, people find Python library in PyPI Googletrans and install it directly by pip command. Now, the latest Python Googletrans version is 3.0.0.
pip install googletrans
'NoneType' object has no attribute 'group'
However, when you execute programs and encounter Python Googletrans attribute error, you had better upgrade it to 3.1.0a0.
pip install googletrans==3.1.0a0
Python Googletrans Auto Detect Language
Calling its translate() method produces not only a translated sentence, but also the source language. Remember the source language, and you will know how to translate back chatbot’s answers to the language your customers used.
def translate(question) :
trans = Translator()
x = trans.translate(question)
return (x.src, x.text)
def trans_back(lang, answer) :
trans = Translator()
x = trans.translate(dest=lang, text=answer)
return x.text
Namely, by this way, the chatbot is able to serve people speaking languages other than French, such as languages of Arabic, German, Spanish, Russian, and even Chinese.
Daily Limits of Googletrans Python
Indeed, Google’s translate API doesn’t allow unlimited use, unless you purchase Google Cloud services to use Google’s official translate API. When exceeding their limit, there is no error but you will find that all operations are dummy and Googletrans Python is not translating. For example, ‘Hello’ in French is ‘Bonjour’, it always gives the result of ‘Bonjour(en) –> Bonjour(en)’. At this time, you possibly used all available free translations for today.
Setting one parameters raise_exception raises exception codes for you to make sure it. The code 429 indicates the case that you have requested intensively. But fortunately, tomorrow you will have more quota to use.
from Googletrans import Translator
trans = Translator(raise_exception=True)
Exception: Unexpected status code "429" from ['translate.googleapis.com']
SECTION 3
French Chatbot Example
In the section, a quick tour shows you the chatting intents, training topics and how the chatbot performs. These materials constitute our chatbot example. You can find more details involved in the previous post.
Categories of Intents
Like our previous example, to design and prepare customers’ intents for chatbot is the first step in training phase. The file containing intent data come to the dataset for machine learning.
[
{"tag": "greeting",
"patterns": ["Hi", "How are you", "Is anyone there?", "Hello", "Good day", "Whats up"],
"responses": ["Hello!", "Good to see you again!", "Hi there, how can I help?"],
"context_set": ""
},
{"tag": "goodbye",
"patterns": ["cya", "See you later", "Goodbye", "Bye", "I am Leaving", "Have a Good day"],
"responses": ["Sad to see you go :(", "Talk to you later", "Goodbye!"],
"context_set": ""
},
{"tag": "age",
"patterns": ["how old", "how old is Eric", "what is your age", "how old are you", "age?"],
"responses": ["I am 18 years old!", "18 years young!"],
"context_set": ""
},
{"tag": "name",
"patterns": ["what is your name", "what should I call you", "whats your name?"],
"responses": ["You can call me Eric.", "I'm Eric!"],
"context_set": ""
},
{"tag": "shop",
"patterns": ["Show me menu", "Give me foods or recipes", "Any recipes and dishes", "Do you have meal types in menu", "could i get something to eat", "I want to order something for meal"],
"responses": [
"You can browse by meal types or skip right to a recipe. What would you like?",
"You can browse by meal types - like breakfast, lunch, dinner, or snack - or skip right to a recipe. For example say breakfast, or avocado toast.",
"To browse by meal types pick breakfast, lunch, dinner, or snack. Or say the name of a dish you'd like to make.",
"You can browse by meal types - like breakfast, lunch, dinner, or snack - or skip right to a recipe. Just say a meal type or the name of a dish."
]
},
{"tag": "hours",
"patterns": ["when are you guys open", "what are your hours", "hours of operation"],
"responses": ["We are open 7am-4pm Monday-Friday!"],
"context_set": ""
}
]
Prepare Model Files and Others
The goal of training is to prepare a TensorFlow Keras model for predictor, the chatbot, to answer users’ questions. Formated files form the model. In addition to the model files, the intermediate data in training process are also required. They are root words, the stemming result, and intent tags, the categories of intents.
def prepare_model(dataset, model_file="model.chatbot") :
''' tokenize '''
words, intents_x, intents_y, intent_tags = tokenize_words(dataset)
''' stemming '''
root_words = stemming(words)
''' Create a new model '''
train_x, train_y = get_train_data(root_words, intents_x, intents_y, intent_tags)
model = build_model(train_x, train_y)
''' save info '''
model.save(model_file)
with open('root-words.json', 'w', encoding='utf-8') as f :
json.dump(root_words, f, indent=2, ensure_ascii=False)
with open('intent-tags.json', 'w', encoding='utf-8') as f :
json.dump(intent_tags, f, indent=2, ensure_ascii=False)
Start to Chat
Subsequently, load model files and others, prompt users to input sentences or phrases, and then feed data into the trained model. Beside Googletrans Python for translation, some techniques of tokenization, stemming, and bag-of-words could be difficult to you if you have not yet read our previous stuff of natural language processing for chatbot and chatbot deep learning.
def chat(model, root_words, intent_tags, dataset):
print("Start talking with the bot (type quit to stop)")
while True:
lang_question = input("You: ")
if lang_question.lower() == "quit": break
lang, question = translate(lang_question)
print("Language: {} Text: {}".format(lang, question))
print(root_words)
''' tokenize '''
#tokens = nltk.word_tokenize(question)
tokens = nltk.regexp_tokenize(question, "[\w']+")
print(tokens)
''' stemming '''
stemmer = nltk.stem.LancasterStemmer()
tokens_tmp = []
for t in tokens:
tokens_tmp.append(stemmer.stem(t.lower()))
print(tokens_tmp)
''' bag of words '''
bag_of_words = []
for w in root_words:
#found = 1 if w in tokens_tmp else 0
if w in tokens_tmp :
found = 1
print(w)
else :
found = 0
bag_of_words.append(found)
print(bag_of_words)
''' model predict to find a tag '''
probilities = model.predict(numpy.array([bag_of_words]))
max_index = numpy.argmax(probilities)
max_probility = probilities[0][max_index]
if max_probility < 0.8 :
print("Sorry, I don't know what you mean. (confidence: {})".format(max_probility))
print(trans_back(lang, "Sorry, I don't know what you mean."))
continue
else :
found_tag = intent_tags[max_index]
''' randomly choose a response according to the found tag '''
for intent in dataset:
if intent['tag'] == found_tag:
answer = numpy.random.choice(intent['responses'])
lang_answer = trans_back(lang, answer)
print("{} (confidence: {})".format(answer, max_probility))
print("Bot: "+lang_answer)
Finally, the chatbot’s chatting example as below shows two facts of detecting language and prediction by English internally. Also, there is a confidence score to indicate the probability.
You: Bonjour
Language: fr Text: Hello
Good to see you again! (confidence: 0.9998430013656616)
Bot: C'est bon de te revoir!
You: je veux quelque chose à manger
Language: fr Text: I want something to eat
To browse by meal types pick breakfast, lunch, dinner, or snack. Or say the name of a dish you'd like to make. (confidence: 0.9999077320098877)
Bot: Pour parcourir les types de repas, choisissez petit-déjeuner, déjeuner, dîner ou collation. Ou dites le nom d'un plat que vous aimeriez faire.
You: heures d'ouverture de la boutique ?
Language: fr Text: shop's open hours?
We are open 7am-4pm Monday-Friday! (confidence: 0.9981029033660889)
Bot: Nous sommes ouverts de 7h à 16h du lundi au vendredi !
You: Je devrais partir maintenant.
Language: fr Text: I should leave now.
Goodbye! (confidence: 0.9886963367462158)
Bot: Au revoir!
FINAL
Conclusion
We suggest a language translation approach trying to achieve a multilingual chatbot example, although Google’s translate API and other vendors’ API both tend to charge service fees upon traffic over a certain threshold.
Truthfully, the NLTK Snowball Stemmer module supports: Arabic, Danish, Dutch, English, Finnish, French, German,Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish and Swedish. Those are enough for you to anchor a direct solution by building a dedicated language model. Hope the number of supported languages gets more very soon.
Thank you for reading, and we have suggested more helpful articles here. If you want to share anything, please feel free to comment below. Good luck and happy coding!