
NLP chatbot can wisely acts as a person in charge of customer service, and we want to concisely reveal the secret of AI(Artificial Intelligence) chatbot by introducing the deep machine learning with Tensorflow and NLTK in Python.
By definition, NLP(Natural Language Processing) is the process that chatbot is able to understand what human is talking about. Therefore, how to build a NLP-based chatbot that can parse natural language by using Python library NLTK(Natural Language Toolkit) is to be discussed.
In addition, before Python AI chatbot can predict or deduce the meaning people express, the bot needs to learn something from training data. We use the famous Python library, Tensorflow, to help chatbot in the machine learning procedure that keeps changing the parameters of weight and bias in the each neural network layer repeatedly.
All codes here are not complicated, so you can easily understand even though you are still students in school. To benefit your learning, we will provide you download link to a zip file thus you can get all source codes for future usage.
Estimated reading time: 17 minutes
EXPLORE THIS ARTICLE
TABLE OF CONTENTS
BONUS
Source Code Download
We have released it under the MIT license, so feel free to use it in your own project or your school homework.
Download Guideline
- Install Python on Windows by clicking Python Downloads, or search a Python setup pack for Linux.
- The installation package for Windows also contains pip install, which allow you to obtain more Python libraries in the future.
SECTION 1
NLP Chatbot Architecture
In the section, some fundamental topics are introduced. In the beginning, we define the limited knowledge of a chatbot by many question-answer pairs. That is, a NLP chatbot know nothing but the chatting intents we define.
Besides, the example had been only tested in Python 3.9 and Tensorflow 2.5.0 on Windows, and Python 3.6 and Tensorflow 1.5.0 on Ubuntu, so for other environment, you should make sure it yourself. Also, we mention why we downgrade Tensorflow version in Linux.
Classify Intents
A python AI chatbot always replies to people with an answer relevant to the intent of his questions. Therefore, what level of understanding the NLP chatbot can catch is equivalent to his capability of classifying people’s intents.
For instance, for a chatbot only capable of saying hello and offering purchase menu, when people raise questions including these two intents, he can identify them and output a proper answer. But for the intents out of range, he doesn’t know what you are talking about.
"tag": "greeting",
"patterns": ["Hi", "How are you", "Is anyone there?", "Hello", "Good day"],
"responses": ["Hello!", "Good to see you again!", "Hi there, how can I help?"],
"tag": "shop",
"patterns": ["Id like to buy something", "whats on the menu"],
"responses": ["We sell chocolate chip cookies for $2!", "Cookies are on the menu!"],
Suppose that greeting and shop as above are the only intents our chatbot understands. Now, look at the following chatting contents for demonstration. There is a confidence value shown with each answer. That indicates the probability of prediction. Assume that we accept only confidence value over a threshold of 0.8, the chatbot will not recognize any result with confidence less than the number.
You: Hello, nice to see you
Good to see you again! (confidence: 0.9998786449432373)
You: I want to buy something
We sell chocolate chip cookies for $2! (confidence: 0.9908439517021179)
You: What time is it?
Sorry, I don't know what you mean. (confidence: 0.7392624020576477)
Natural Language Toolkit (NLTK)
The library NLTK provides easy-to-use interfaces for Python programmers to work with human language data. At the very beginning of building a NLTK chatbot, you need to load a pre-trained Punkt tokenizer package by nltk.download('punkt').
Primarily, the Punkt tokenizer provides functions that help complete the following tasks in each phase.
- tokenize sentences to be words
- perform stemming algorithm
- generate bag-of-words representation as training data
Because you just need to load it once, we write codes in a separated Python file.
''' natural language toolkit '''
import nltk
nltk.download('punkt')
Tokenization is the process of splitting sentences into a list of tokens, mostly referred as words. A tokenization algorithm can split the sentence such as “Reading books can strengthen your comprehension” into the words “Reading”, “can”, “strengthen”, “your”, and “comprehension”.
Stemming is the process of reducing morphological variant words into root words. A stemming algorithm or program reduces the words, e.g., “chocolates”, “chocolatey”, “choco” to the root word, “chocolate”.
Sometimes, we call it a stemmer in Python. Two popular stemmers in Python are Porter Stemmer(since 1980) and Lancaster Stemmer, but the latter one is newer and more famous to developers. You can get them from Python library nltk.
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
The bag-of-words is a natural language processing technique, which extracts features from text data. More precisely, it describes the occurrence of words within a document or a set of root words, but discards the order or structure information in the document.
For root words such as [‘eat’, ‘for’, ‘it’, ‘get’, ‘day’, ‘good’, ‘friday’], we can express the phrase “Good day” in bag-of-words representation to be [0, 0, 0, 0, 1, 1, 0]. As its numerical representation, instead of texts, the machine learning process in neural network is possibly operational.
Overview of Python AI Chatbot Learning
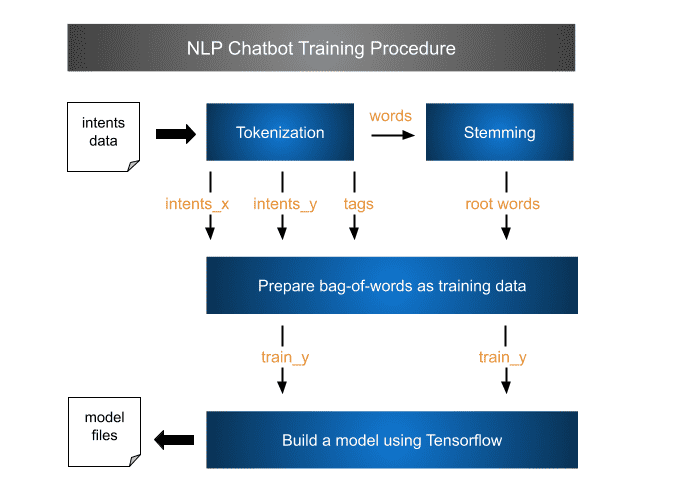
That illustrates what steps we used to train a chatbot. Accompanied with source codes, you will more easily understand the intermediate data between modules.
Tensorflow Execution Environment
Indeed, building an environment Tensorflow can run is not easy on Linux. Installing Tensorflow should consider CPU’s capability. The precompiled binaries of Tensorflow versions large than 1.5 use AVX instructions that are not supported by older CPUs, so you have to downgrade Tensorflow.
Intuitively, you may execute the following instructions to downgrade it, but you should get failed.
pip uninstall tensorflow
pip install tensorflow==1.5.0
Tensorflow has no built binary version of 1.5.0, so you need to search its wheel files of version 1.5.0 for the one compatible with your Python version such as 3.6. Then execute the pip command below.
pip install https://files.pythonhosted.org/packages/04/79/a37d0b373757b4d283c674a64127bd8864d69f881c639b1ee5953e2d9301/tensorflow-1.5.0-cp36-cp36m-manylinux1_x86_64.whl
SECTION 2
Process NLP Chatbot Dataset
To make a NLP chatbot learn natural language under Tensorflow, we need numerical data rather than textual data. Subsequently, we will go through steps of converting chatting intents in texts into the bag-of-words representation in numbers to be used as training data.
Data for Intents
A specific dataset of question-answer correspondences is used to configure the Python AI chatbot in the style we want, so that he can catch your intents from chatting contents. There are 6 categories/tags of intents data in our example.
[
{"tag": "greeting",
"patterns": ["Hi", "How are you", "Is anyone there?", "Hello", "Good day", "Whats up"],
"responses": ["Hello!", "Good to see you again!", "Hi there, how can I help?"],
"context_set": ""
},
{"tag": "goodbye",
"patterns": ["cya", "See you later", "Goodbye", "Bye", "I am Leaving", "Have a Good day"],
"responses": ["Sad to see you go :(", "Talk to you later", "Goodbye!"],
"context_set": ""
},
{"tag": "age",
"patterns": ["how old", "how old is tim", "what is your age", "how old are you", "age?"],
"responses": ["I am 18 years old!", "18 years young!"],
"context_set": ""
},
{"tag": "name",
"patterns": ["what is your name", "what should I call you", "whats your name?"],
"responses": ["You can call me Tim.", "I'm Tim!", "I'm Tim aka Tech With Tim."],
"context_set": ""
},
{"tag": "shop",
"patterns": ["Id like to buy something", "whats on the menu", "what do you recommend?", "could i get something to eat"],
"responses": ["We sell chocolate chip cookies for $2!", "Cookies are on the menu!"],
"context_set": ""
},
{"tag": "hours",
"patterns": ["when are you guys open", "what are your hours", "hours of operation"],
"responses": ["We are open 7am-4pm Monday-Friday!"],
"context_set": ""
}
]
Just a simple function load_data() can load each category that contains a tag name, question patterns, and answer responses. We call the loaded result as a dataset.
def load_data(json_file='intents.json') :
'''
load intents file
intents => { tag, patterns, responses, context_set }
'''
with open(json_file) as f:
dataset = json.load(f)
return dataset
Tokenize Sentences into Words
The sentences we are going to tokenize are not only question patterns, but also answer responses. The reason is that words in answers are as important as the words in questions when NLP chatbot is catching the meaning. The function tokenize_words() results in words and intents_x for X-axis input, and intents_y and intent_tags for Y-axis output.
def tokenize_words(dataset) :
words = []
intents_x = []
for intent in dataset:
for p in intent['patterns']+intent['responses']: # consider both Q & A
#tokens = nltk.word_tokenize(p)
tokens = nltk.regexp_tokenize(p, "[\w']+") # can remove ?
words.extend(tokens)
intents_x.append(tokens)
intent_tags = []
intents_y = []
for intent in dataset:
for p in intent['patterns']+intent['responses']: # consider both Q & A
intents_y.append(intent["tag"])
if intent['tag'] not in intent_tags:
intent_tags.append(intent['tag'])
intent_tags = sorted(intent_tags)
return (words, intents_x, intents_y, intent_tags)
There are 4 kinds of output data. One of them is the words that would include duplicated tokens such as the following example data. In the next stemming phase, it will be reduced as root_words with only unique words.
['Hi', 'How', 'are', 'you', 'Is', 'anyone', 'there', 'Hello', 'Good', 'day', 'Whats', 'up', 'Hello', 'Good', 'to', 'see', 'you', 'again', 'Hi', 'there', 'how', 'can', 'I', 'help', 'cya', 'See', 'you', 'later', 'Goodbye', 'Bye', 'I', 'am', 'Leaving', 'Have', 'a', 'Good', 'day', 'Sad', 'to', 'see', 'you', 'go', 'Talk', 'to', 'you', 'later', 'Goodbye', 'how', 'old', 'how', 'old', 'is', 'tim', 'what', 'is', 'your', 'age', 'how', 'old', 'are', 'you', 'age', 'I', 'am', '18', 'years', 'old', '18', 'years', 'young', 'what', 'is', 'your', 'name', 'what', 'should', 'I', 'call', 'you', 'whats', 'your', 'name', 'You', 'can', 'call', 'me', 'Tim', "I'm", 'Tim', "I'm", 'Tim', 'aka', 'Tech', 'With', 'Tim', 'Id', 'like', 'to', 'buy', 'something', 'whats', 'on', 'the', 'menu', 'what', 'do', 'you', 'recommend', 'could', 'i', 'get', 'something', 'to', 'eat', 'We', 'sell', 'chocolate', 'chip', 'cookies', 'for', '2', 'Cookies', 'are', 'on', 'the', 'menu', 'when', 'are', 'you', 'guys', 'open', 'what', 'are', 'your', 'hours', 'hours', 'of', 'operation', 'We', 'are', 'open', '7am', '4pm', 'Monday', 'Friday']
Moreover, let’s compare two approaches about tokenization. The nltk.word_tokenize() is a intuitive way to perform tokenization, but it can not solve the issue of question marks. Alternatively, we use a regular expression approach, nltk.regexp_tokenize(), which can remove question marks. For the example question such as q="Is anyone there?", compare the results by using two tokenization methods as below.
| method | result |
|---|---|
| nltk.word_tokenize(q) | [‘Is’, ‘anyone’, ‘there’, ‘?’] |
| nltk.regexp_tokenize(q, “[\w’]+”) | [‘Is’, ‘anyone’, ‘there’] |
Obviously, the issue of question marks is solved.
Stemming Algorithm
The stemming program, nltk.stem.LancasterStemmer(), can find root_words from words. Of course, before stemming, we need to make all words to be lowercase.
def stemming(words) :
'''
A word stemmer based on the Lancaster (Paice/Husk) stemming algorithm.
For finding the base or root of words.
'''
stemmer = nltk.stem.LancasterStemmer()
words_tmp = []
for w in words :
words_tmp.append(stemmer.stem(w.lower()))
root_words = sorted(set(words_tmp)) # set() will remove duplications
return root_words
After taking duplicated tokens out, and sorting tokens, the root_words appears as below. These root words do contain something like ‘ak’ that we don’t know its explanation, however, the words reduction will really make computation resources less in learning phase.
['18', '2', '4pm', '7am', 'a', 'ag', 'again', 'ak', 'am', 'anyon', 'ar', 'buy', 'bye', 'cal', 'can', 'chip', 'chocol', 'cooky', 'could', 'cya', 'day', 'do', 'eat', 'for', 'friday', 'get', 'go', 'good', 'goodby', 'guy', 'hav', 'hello', 'help', 'hi', 'hour', 'how', 'i', "i'm", 'id', 'is', 'lat', 'leav', 'lik', 'me', 'menu', 'monday', 'nam', 'of', 'old', 'on', 'op', 'recommend', 'sad', 'see', 'sel', 'should', 'someth', 'talk', 'tech', 'the', 'ther', 'tim', 'to', 'up', 'we', 'what', 'when', 'with', 'year', 'yo', 'you', 'young']
Bag of Words
Based on the sorted root_words list, we convert all questions and answers into numeric data in the bag-of-words representation as mentioned in Section 1.
All bag-of-words for questions and answers are the data on X-axis used as input, and all bag-of-words for categories are data on Y-axis referred as output. In the process of training NLP chatbot under Tensorflow , we refer to the input as training data, and the output as a category.
As the defined chatting intents in Section 2, each question-answer pair belongs to a tag or category. These following programs show, for each intents_x, how to get its bag-of-words, and corresponding bag-of-words of intent_tags. Note that output_row is also of bag-of-words format.
def get_train_data(root_words, intents_x, intents_y, intent_tags) :
stemmer = nltk.stem.LancasterStemmer()
training = []
output = []
for i in range(len(intents_x)):
''' for x '''
bag_of_words = []
words_tmp = []
for w in intents_x[i] :
words_tmp.append(stemmer.stem(w.lower()))
for w in root_words:
found = 1 if w in words_tmp else 0
bag_of_words.append(found)
training.append(bag_of_words)
''' for y '''
output_row = [0] * len(intent_tags)
output_row[intent_tags.index(intents_y[i])] = 1
output.append(output_row)
train_x = numpy.array(training)
train_y = numpy.array(output)
return (train_x, train_y)
Finally, the function get_train_data() creates two numpy array data, train_x and train_x, which are essential training data.
SECTION 3
Build Tensorflow Chatbot Model
Each chatbot should load a trained model or build a new model to start chatting service. In other words, any built model can be stored as files that will avoid time-consuming building procedure each time the system starts up.
Load The Existing Model
If you already have a learned model, just load it to start chatting; otherwise, build a new one. the function prepare_model() returns a model, root words, and tags from dataset. These 3 elements are essential to the function chat() which will be mentioned in Section 4.
First, two functions tokenize_words() and stemming(), discussed in Section 2, perform prerequisite tasks for all intents data.
Python Tensorflow allows you to save a trained chatbot model as a directory such as model.chatbot in Windows, even though we call it a model file. But in Linux, some previous verison of Python libraries do save it as files.
If no existing model, the function get_train_data() produces data in bag-of-words format for another function build_model() to build a a new model. Finally, save it by a member function model.save(), thus systems can load it in the next start-up time.
def prepare_model(dataset, model_file="model.chatbot") :
''' tokenize '''
words, intents_x, intents_y, intent_tags = tokenize_words(dataset)
''' stemming '''
root_words = stemming(words)
if os.path.isdir(model_file) or os.path.isfile(model_file):
''' Load existing model '''
model = tf.keras.models.load_model(model_file)
print("Loading model successfully")
else :
''' Create a new model '''
train_x, train_y = get_train_data(root_words, intents_x, intents_y, intent_tags)
model = build_model(train_x, train_y)
model.save(model_file)
return (model, root_words, intent_tags)
In the example, the output intent tags are listed as below.
['greeting', 'goodbye', 'age', 'name', 'shop', 'hours']
Fix Loading Error
AttributeError: 'str' object has no attribute 'decode'
On Linux, if calling the method tf.keras.models.load_model() cause error as above, the solution is to downgrade Python library h5py if its version is large than 3.
pip uninstall h5py
pip install h5py==2.10.0
Build a Chatbot Model by Tensorflow
So far, let’s open the critical black box build_model() for discussion. This function takes train_x and train_y as training data. To build a chatbot model, we use keras in Tensorflow to add train_x as input layer, train_y as output layer, and two internal layers as hidden layers.
The batch_size is usually set to a value between 1 and the total number of examples in the training dataset. In our example, the total number of examples is 41.
train_x.shape = (41, 72)
train_y.shape = (41, 6)
Usually, the output layer needs an activation function. We set it as softmax that is proper for categorical model like our NLTK chatbot.
def build_model(train_x, train_y) :
epochs = 1000
batch_size = 16
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(batch_size, input_shape=(len(train_x[0]),))) # input layer
model.add(tf.keras.layers.Dense(batch_size)) # hidden layer 1
model.add(tf.keras.layers.Dense(batch_size)) # hidden layer 2
model.add(tf.keras.layers.Dense(len(train_y[0]), activation='softmax')) # output layer
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=0)
''' Evaluate accuracy of the model '''
model.summary() # for debugging
test_loss, test_acc = model.evaluate(train_x, train_y, verbose=0)
print("\nTested Loss:{} Acc:{}".format(test_loss, test_acc))
return model
Typically, learning in neural networks seeks to minimize the error in order to make the evaluated weight and bias values more accurate. A loss function calculate a value to estimate the loss, and then help to reduce the error.
When using loss function, the smaller loss value is, the more precise weight and bias values are. In general, popular loss function algorithms could be mean squared error or cross entropy error. We choose the latter one denoted as categorical_crossentropy in Python programs.
One epoch is a measurement used in machine learning to denote the number of passing through entire training dataset by algorithm. If the batch size is the whole training dataset, then the number of epochs is the number of iterations.
The function model.evaluate() compares accuracy for each epoches. More epochs will definitely produce a trained model in less loss. However, it takes more computation time and resources. There is a tension between the size of epoch and system resources.
Tested Loss:9.136813605437055e-05 Acc:1.0 (epochs = 1000)
Tested Loss:0.03157765418291092 Acc:1.0 (epochs = 100)
For debugging, the tool function model.summary() abstracts the information of layers, layer shapes, and parameters. You can refer the parameter column to be the number of weight and bias values in each layers of the model.
Model: "sequential"
Layer (type) Output Shape Param #
dense (Dense) (None, 16) 1168
dense_1 (Dense) (None, 16) 272
dense_2 (Dense) (None, 16) 272
dense_3 (Dense) (None, 6) 102
Total params: 1,814
Trainable params: 1,814
Non-trainable params: 0
SECTION 4
Chat with NLP AI Chatbot
Chatting with the Python AI chatbot is to predict what happens when you put talking sentences to a trained model. Even though the test sentences are not exactly the same as any one of our dataset, he can picked up the right category.
When you ask the NLP chatbot, he can predict which category your speeches belong to and randomly selects an answer from all available responses, so that answers are a little different and not boring. Each response is accompanied with an acceptable confidence score to indicate how accurate the recognition is.
Tokenize Words and Stemming
According to the root words extracted in Section 2, let us test a sentence. The sentence “Tell me your name” will become tokens of [‘Tell’, ‘me’, ‘your’, ‘name’] after tokenization. Then the stemming program reduces words to be root words, [‘tel’, ‘me’, ‘yo’, ‘nam’].
Produce Bag-of-Words for Prediction
Let’s begin to chat. When you enter the sentence “Tell me your name”, the chatbot shows root words, tokenized words, and stemming words. The last 3 stemming words exist in root words, so bag-of-words is generated based on these 3 ones and have 3 1’s in this sentence’s one-hot representation.
Start talking with the bot (type quit to stop)
You: Tell me your name
['18', '2', '4pm', '7am', 'a', 'ag', 'again', 'ak', 'am', 'anyon', 'ar', 'buy', 'bye', 'cal', 'can', 'chip', 'chocol', 'cooky', 'could', 'cya', 'day', 'do', 'eat', 'for', 'friday', 'get', 'go', 'good', 'goodby', 'guy', 'hav', 'hello', 'help', 'hi', 'hour', 'how', 'i', "i'm", 'id', 'is', 'lat', 'leav', 'lik', 'me', 'menu', 'monday', 'nam', 'of', 'old', 'on', 'op', 'recommend', 'sad', 'see', 'sel', 'should', 'someth', 'talk', 'tech', 'the', 'ther', 'tim', 'to', 'up', 'we', 'what', 'when', 'with', 'year', 'yo', 'you', 'young']
['Tell', 'me', 'your', 'name']
['tel', 'me', 'yo', 'nam']
me
nam
yo
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
I'm Tim aka Tech With Tim. (confidence: 0.999953031539917)
You:
The category is correctly about asking names with a randomly selected response sentence saying I’m Tim aka Tech With Tim. There is a confidence score, 0.999953031539917, indicating how accurate this prediction is.
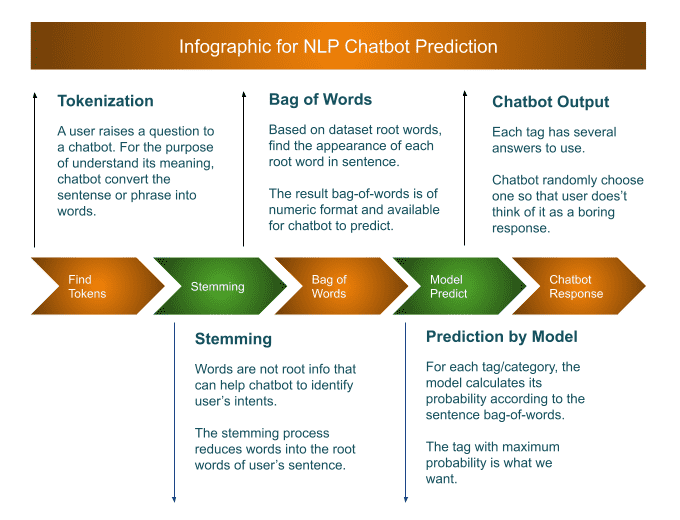
Before reading the source codes of chat(), look at the info-graphics that truly step by step shows the procedure of prediction.
def chat(model, root_words, intent_tags, dataset):
print("Start talking with the bot (type quit to stop)")
while True:
question = input("You: ")
if question.lower() == "quit": break
print(root_words)
''' tokenize '''
#tokens = nltk.word_tokenize(question)
tokens = nltk.regexp_tokenize(question, "[\w']+")
print(tokens)
''' stemming '''
stemmer = nltk.stem.LancasterStemmer()
tokens_tmp = []
for t in tokens:
tokens_tmp.append(stemmer.stem(t.lower()))
print(tokens_tmp)
''' bag of words '''
bag_of_words = []
for w in root_words:
#found = 1 if w in tokens_tmp else 0
if w in tokens_tmp :
found = 1
print(w)
else :
found = 0
bag_of_words.append(found)
print(bag_of_words)
''' model predict to find a tag '''
probilities = model.predict(numpy.array([bag_of_words]))
max_index = numpy.argmax(probilities)
max_probility = probilities[0][max_index]
if max_probility < 0.8 :
print("Sorry, I don't know what you mean. (confidence: {})".format(max_probility))
continue
else :
found_tag = intent_tags[max_index]
''' randomly choose a response according to the found tag '''
for intent in dataset:
if intent['tag'] == found_tag:
print("{} (confidence: {})".format(numpy.random.choice(intent['responses']), max_probility))
Now, you can talk to a bot, the NLP-based chatbot in Keras model, about what to buy, when the store is open, and even his name and age.
You: hi
Hello! (confidence: 0.9998430013656616)
You: I want something to eat
We sell chocolate chip cookies for $2! (confidence: 0.9786539673805237)
You: How old are you
18 years young! (confidence: 0.9999953508377075)
You: what is your name
I'm Tim! (confidence: 0.9998480081558228)
You: shop's open hours?
We are open 7am-4pm Monday-Friday! (confidence: 0.9981029033660889)
You: I should leave now
Goodbye! (confidence: 0.9886963367462158)
FINAL
Conclusion
This is a simplified machine learning example used in the field of AI chatbot by Python Tensorflow and NLTK. Of course, the intent data contain so little sentences as not to face with user’s mass intents in the real world. If interested, add more contents and make the nlp chatbot rich with intelligence.
If you want more computing resources, study the parallel execution in Python, which may improve the performance.
Thank you for reading, and we have suggested more helpful articles here. If you want to share anything, please feel free to comment below. Good luck and happy coding!
Suggested Reading
- Googletrans Python Example for A French Chatbot
- 3 Steps Line Notify API Inform Group Member by Token