
Using web scraping techniques to add a weather crawler module in your apps can help users to crawl temperature and more weather info as they want. For weather inquiry, you can call weather APIs provided by Bureau of Meteorology, or crawl Google and some weather channels.
All codes here are not complicated, so you can easily understand even though you are still students in school. To benefit your learning, we will provide you download link to a zip file thus you can get all source codes for future usage.
Estimated reading time: 9 minutes
EXPLORE THIS ARTICLE
TABLE OF CONTENTS
BONUS
Source Code Download
We have released it under the MIT license, so feel free to use it in your own project or your school homework.
Download Guideline
- Install Python on Windows by clicking Python Downloads, or search a Python setup pack for Linux.
- The installation package for Windows also contains pip install, which allow you to obtain more Python libraries in the future.
SECTION 1
Crawl AccuWeather Channel
To crawl temperature from weather channels probably encounters problems associated with languages, locale places, blocking and so on. The section presents a indirect method that leverages the capability of Google Search.
Location in HTTP GET Not Allowed
The first step to weather inquiry is to input a location. If weather channel websites allow HTTP GET data, we have no problem. However, most of them use POST data for the input of city or zip code. As below.
Indirect Weather Scraping
Rather than directly searching accuweather.com, we get help in Google Search. For example, scraping weather in Berlin will be done by
https://www.google.com/search?q=weather+accuweather+Berlin
The result contains more than one <a> tags. Using BeautifulSoup, find the one best fitting your rule. The rule is that the attribute href has leading string of https://www.accuweather.com/.
<a href="https://www.accuweather.com/en/de/berlin/10178/weather-forecast/178087"
data-ved="2ahUKEwj1-6LlqLbvAhXIURUIHaqzBRIQFjABegQIARAE"
ping="/url?sa=t&source=web&rct=j&url=https://www.accuweather.com/en/de/berlin/10178/weather-forecast/178087&ved=2ahUKEwj1-6LlqLbvAhXIURUIHaqzBRIQFjABegQIARAE">
Next, retrieve the url https://www.accuweather.com/en/de/berlin/10178/weather-forecast/178087.
To crawl weather info for Berlin, find the wcard first, and then look for the following CSS class in wcard.
- cur-con-weather-card__subtitle : find the class for current time.
- weather-icon : find the class for weather icon file.
- temp : find the class for temperature.
- phrase : find the class for the phrase to describe weather.
<a class="cur-con-weather-card card-module non-ad content-module lbar-panel" href="/en/de/berlin/10178/current-weather/178087">
<div class="cur-con-weather-card__body">
<div class="cur-con-weather-card__panel">
<p class="cur-con-weather-card__subtitle">8:41 AM</p>
<div class="forecast-container">
<img class="weather-icon" src="/images/weathericons/06.svg" width="88" height="88" />
<div class="temp-container">
<div class="temp">2°<span class="after-temp">C</span></div>
</div>
</div>
</div>
</div>
<div class="spaced-content">
<span class="phrase">Mostly cloudy</span>
</div>
</a>
Python scripts are in get_accuweather().
def get_accuweather(location) :
# Get the content of web page
the_url = "https://www.google.com/search?hl=en&q=weather+accuweather+{}".format(location)
r_text = get_webpage(the_url)
# Crawl and analyze
# Get the url from Google results
soup = BeautifulSoup(r_text, "html.parser")
google_results = soup.find_all(href=re.compile("https://www.accuweather.com/"))
# Get content from the url
weather_page = ""
for a in google_results :
if a['href'].find('https://www.accuweather.com/') == 0 and '/weather-forecast/' in a['href'] :
# e.g https://www.accuweather.com/en/de/berlin/10178/weather-forecast/178087
the_url = a['href']
weather_page = get_webpage(the_url)
break
# Ignore invalid location
if weather_page == "" :
return [location, "N/A"]
# Crawl and analyze the web page
soup = BeautifulSoup(weather_page, "html.parser")
wcard = soup.find("a", attrs={"class" : "cur-con-weather-card"})
current = wcard.find("p", attrs={"class" : "cur-con-weather-card__subtitle"}).text.strip()
icon = "https://www.accuweather.com"+wcard.find("img", attrs={"class" : "weather-icon"})['src']
icon_img = "<img src='{}' width='44' height='44'>".format(icon)
phrase = wcard.find("span", attrs={"class" : "phrase"}).text
temperature = wcard.find("div", attrs={"class" : "temp"}).text
return [current, location, temperature, icon_img, phrase]
Search for weather in Mumbai, India. As depicted below, ムンバイ is the Japanese name of Mumbai. Auto language translation should be done by accuweather.com or Google Search.
Moreover, the indirect scraping approach identifies that Bösingfeld is a small town in Germany. Even though you input a locale place not well-known, it can be found.
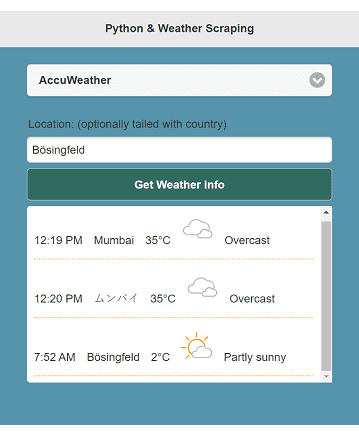
["12:19 PM", "Mumbai", "35°C", "<img src='https://www.accuweather.com/images/weathericons/8.svg' width='44' height='44'>", "Overcast"]
["12:20 PM", "ムンバイ", "35°C", "<img src='https://www.accuweather.com/images/weathericons/8.svg' width='44' height='44'>", "Overcast"]
["7:52 AM", "Bösingfeld", "2°C", "<img src='https://www.accuweather.com/images/weathericons/3.svg' width='44' height='44'>", "Partly sunny"]
SECTION 2
Crawl WeatherAvenue Channel
The section also applies the indirect way for another weather channel. Truly, this channel has some drawbacks. Indeed, our crawler can reveal quality of weather channels by comparison.
Indirect Approach
Like accuweather, our weather crawler goes searching Google by the keywords.
https://www.google.com/search?q=weather+weatheravenue+Berlin
The result contains more than one <table> tags. Using BeautifulSoup, find the one best fitting your rule. The rule is that the attribute href has tailing string of -weather.html.
<a href="https://www.weatheravenue.com/en/europe/de/berlin/berlin-weather.html"
data-ved="2ahUKEwj-0-P4oLfvAhUMK6YKHZ1yCS8QFjABegQIBhAD"
ping="/url?sa=t&source=web&rct=j&url=https://www.weatheravenue.com/en/europe/de/berlin/berlin-weather.html&ved=2ahUKEwj-0-P4oLfvAhUMK6YKHZ1yCS8QFjABegQIBhAD"><br>
<h3 class="LC20lb DKV0Md">Weather Berlin Germany - Weather Avenue</h3>
<div class="TbwUpd NJjxre">
<cite class="iUh30 Zu0yb qLRx3b tjvcx">www.weatheravenue.com<span class="dyjrff qzEoUe"> › ... › Germany › Berlin</span></cite>
</div>
</a>
Next, retrieve the url https://www.weatheravenue.com/en/europe/de/berlin/berlin-weather.html.
To crawl temperature and other weather info for Berlin, find the wcard first, and then look for the following html attributes in wcard, which is html tag <table>.
- <div align="center"> : find the attribute for current date.
- style=’vertical-align:middle;’ : find the attribute for weather icon file.
- degreeC : find the class for temperature Celsius.
- degreeF : find the class for temperature Fahrenheit.
- phrase : find the parent of parent of tag <img> for the phrase to describe weather.
<table ..... >
<tr>
<td ..... >
<div align="center">
<h2 style="font-weight:bold;"> Weather <span itemprop="name" style="">Berlin</span> </h2> - Wednesday 17 March 2021
</div>
</td>
</tr>
<tr>
<td ..... >
<div align="center">
<span ..... >
<img src='https://cdn.weatheravenue.com/img/cold_32.png' height='32' width='32' border='0' style='vertical-align:middle;position:absolute;top:42px;left:102px;' title='Temperature' alt='Temperature'/>
</span>
<br/> Overcast <br/><br/>
</div>
</td>
<td ..... >
.....
<span class='degreeC'>3°C </span><span class='degreeF'>37°F </span>
.....
</td>
Python scripts are in get_weatheravenue().
def get_weatheravenue(location) :
# Get the content of web page
the_url = "https://www.google.com/search?hl=en&q=weather+weatheravenue+{}".format(location)
r_text = get_webpage(the_url)
# Crawl and analyze
# Get the url from Google results
soup = BeautifulSoup(r_text, "html.parser")
google_results = soup.find_all(href=re.compile("https://www.weatheravenue.com/"))
# Get content from the url
weather_page = ""
for a in google_results :
tail = '-weather.html'
if a['href'].find(tail) == len(a['href']) - len(tail) :
the_url = a['href']
weather_page = get_webpage(the_url)
break
# Ignore invalid location
if weather_page == "" :
return [location, "N/A"]
# Crawl and analyze the web page
soup = BeautifulSoup(weather_page, "html.parser")
wcard = soup.find("table", attrs={"class" : "weather-border"})
current = wcard.find("div", attrs={"align" : "center"}).text.split('-')[1].strip()
temperature_c = wcard.find("span", attrs={"class" : "degreeC"}).text
temperature_f = wcard.find("span", attrs={"class" : "degreeF"}).text
temperature = "{}/{}".format(temperature_c, temperature_f)
icon = wcard.find("img", attrs={"style" : "vertical-align:middle;"})
icon_img = "<img src='{}' width='44' height='44'>".format(icon['src'])
phrase = icon.parent.parent.text.strip()
return [current, location, temperature, icon_img, phrase]
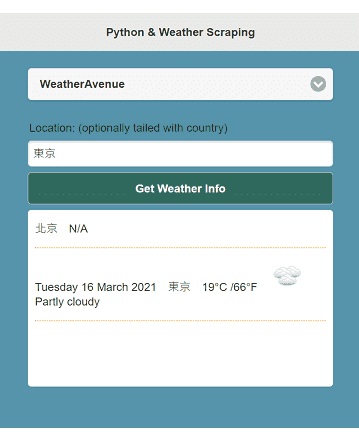
["北京", "N/A"]
["Tuesday 16 March 2021", "東京", "19°C /66°F ", "<img src='https://cdn.weatheravenue.com/img/weather128/cloudly.png' width='44' height='44'>", "Partly cloudy"]
As above, unfortunately, weateravenue.com can recognize Japanese, but not Chinese. For example, 北京 is the Chinese name of Beijing, but 東京 is both Chinese and Japanese name of Tokyo.
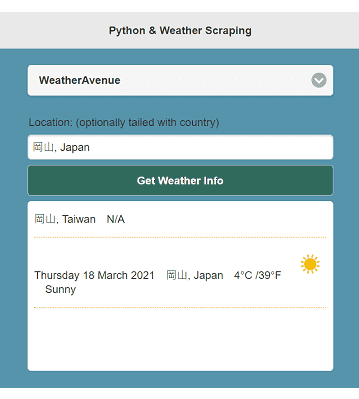
["岡山, Taiwan", "N/A"]
["Tuesday 16 March 2021", "岡山, Japan", "16°C /61°F ", "<img src='https://cdn.weatheravenue.com/img/weather128/cloudly.png' width='44' height='44'>", "Partly cloudy"]
As above, there is a city named as 岡山 in both Taiwan and Japan. But weateravenue.com is not aware of the former one.
SECTION 3
Crawl Google Search Weather
The final approach is direct crawling. It seems better than the previous two methods.
Direct Weather Scraping
The approach just searches Google by the keywords.
https://www.google.com/search?q=weather+Berlin
Compared to previous approaches, Google Search is easier. For Berlin, just find the attribute id for the following.
- wob_dts : find the id for current time.
- wob_tci : find the id for weather icon file.
- wob_tm : find the id for temperature Celsius.
- wob_ttm : find the id for temperature Fahrenheit.
- wob_dcp : find the id for the phrase to describe weather.
- wob_loc : find the id for Google identified location including country or province.
- wob_pp : find the id for precipitation.
- wob_hm : find the id for humidity.
<!-- Picture illustrating the weather -->
<img class="wob_tci" alt="Partly cloudy" src="//ssl.gstatic.com/onebox/weather/64/partly_cloudy.png" id="wob_tci">
<div jscontroller="a3bY8" class="Ab33Nc" aria-level="3" role="heading">
<div>
<!-- Temperature in °C(°Celsius) and °F(°Fahrenheit) -->
<div class="vk_bk TylWce">
<span class="wob_t TVtOme" id="wob_tm" style="display:inline">23</span>
<span class="wob_t" id="wob_ttm" style="display:none">73</span>
</div>
<!-- Identified location -->
<div class="wob_loc mfMhoc" id="wob_loc">Linkou District, New Taipei City</div>
<!-- The time of weather reports -->
<div class="wob_dts" id="wob_dts">Tuesday 9:00 AM</div>
<!-- Phrase describing the weather -->
<div class="wob_dcp" id="wob_dcp"><span id="wob_dc">Partly cloud</span></div>
<!-- Percentage of falling rain or snow -->
<div>Precipitation: <span id="wob_pp">1%</span></div>
<!-- Concentration of water vapor present in the air -->
<div>Humidity: <span id="wob_hm">68%</span></div>
Python scripts are in get_google().
def get_google(location) :
# Get the content of web page
the_url = "https://www.google.com/search?hl=en&q=weather+{}".format(location)
r_text = get_webpage(the_url)
# Crawl and analyze
soup = BeautifulSoup(r_text, "html.parser")
current = soup.find("div", attrs={"id" : "wob_dts"}).text.strip()
temperature_c = soup.find("span", attrs={"id" : "wob_tm"}).text.strip()
temperature_f = soup.find("span", attrs={"id" : "wob_ttm"}).text.strip()
temperature = "{}°C/{}°F".format(temperature_c, temperature_f)
icon = soup.find("img", attrs={"id" : "wob_tci"})
icon_img = "<img src='{}' width='44' height='44'>".format(icon['src'])
phrase = soup.find("div", attrs={"id" : "wob_dcp"}).text.strip()
loc = soup.find("div", attrs={"id" : "wob_loc"}).text.strip()
precipitation = "precipitation: " + soup.find("span", attrs={"id" : "wob_pp"}).text.strip()
humidity = "humidity: " + soup.find("span", attrs={"id" : "wob_hm"}).text.strip()
return [current, location, temperature, icon_img, phrase, precipitation, humidity, loc]
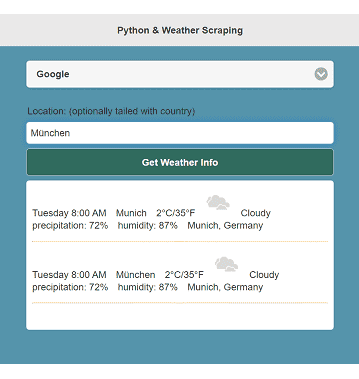
["Thursday 3:00 AM", "Munich", "0°C/32°F", "<img src='//ssl.gstatic.com/onebox/weather/64/cloudy.png' width='44' height='44'>", "Cloudy", "precipitation: 7%", "humidity: 84%", "Munich, Germany"]
["Thursday 3:00 AM", "München", "0°C/32°F", "<img src='//ssl.gstatic.com/onebox/weather/64/cloudy.png' width='44' height='44'>", "Cloudy", "precipitation: 7%", "humidity: 84%", "Munich, Germany"]
German München and Munich locate the same city, and Google Search identify that it is Munich, Germany.
Precipitation is the potential rate of falling rain or snow out of the sky. Humidity is the percentage of water vapor actually in the air.
CGI Configuration for Python Web Apps
You have seen that all the weather scraping results are presented in HTML layout. We treat Python as server-site scripts which serve requests from JS scripts in browsers. In our previous post, we have introduced the configuring Apache CGI for Python web applications about Windows, Ubuntu, and CentOS.
<div data-role="page" style="background:#5594ab;">
<div data-role="header">
<p class="center">Python & Weather Scraping</p>
</div>
<div data-role="content">
<div class="main-content">
<select id="channel-list" class="align-left"></select>
<legend>Location: (optionally tailed with country)</legend>
<input type="text" id="place-field" class="align-left"></input>
<button class="ui-btn ui-corner-all" id="weather">Get Weather Info</button>
<div id="response"></div>
</div>
</div>
</div>
.....
<script>
$(document).ready(function() {
for(id in channels) {
$("#channel-list").append(
"<option value='" + channels[id] + "'>" + channels[id] + "</option>");
}
$("#channel-list").selectmenu("refresh", true);
});
$('#place-field').on("keyup", function(e) {
if (e.keyCode == 13) send($("#place-field").val());
});
$('#weather').on("click", function() {
send($("#place-field").val());
});
function send(place) {
channel = $("#channel-list").find(":selected").val()
console.log(place+" "+channel);
$.ajax({
url: "weatherscraping.py",
type: "POST",
data: { location: place, channel: channel },
success: function(r) {
console.log(r)
obj = r;
html = "<p>";
for (id in obj) {
html += obj[id] + " ";
}
$("#response").append(html+"</p><hr>").scrollTop($("#response")[0].scrollHeight);
},
});
}
FINAL
Conclusion
Weather scraping makes your site provide more services for users. The Apache CGI approach mentioned allow browser clients to request the weather crawler directly to crawl temperature, weather icon, description and more.
Thank you for reading, and we have suggested more helpful articles here. If you want to share anything, please feel free to comment below. Good luck and happy coding!
Suggested Reading
- Telegram Bot API Send Weather Message by Python
- Python Web Scraping using BeautifulSoup in 3 Steps
- Solving Post JSON to Python CGI FieldStorage Error